Ember Data Progress Update
A month ago, we told you about our plans for stabilizing Ember Data. I'd like to give you an update on the status of those efforts.
First, though, I'd like to thank everyone who has been contributing to Ember Data. As an open source project, a healthy, active community is our lifeblood. In particular, I want to call out Igor Terzic, Stefan Penner, Paul Chavard and Gordon Hempton for going above and beyond the call of duty.
Thanks to their efforts, we've been making steady progress towards triaging and reviewing pull requests and issues.
Additionally, Yehuda and I have been able to devote significant time to working on Ember Data thanks to the financial support of Addepar. They have my sincere thanks for being a company that understands the importance of investing in open source.
A New Focus
Imagine that you are starting a new job as a developer on an existing server-side web application. On the first day, you begin the process of familiarizing yourself with the codebase.
Since you have experience with the server-side MVC framework that this company uses, the day is going well. You see that the templates are cleanly separated from the controller logic, which is itself cleanly separated from the models.
But, wait: something looks amiss in the model code. You take a closer look.
Instead of using an ORM (like ActiveRecord), which queries the database for you and automatically turns the results into objects, it looks like they're issuing queries manually.
"No problem," you think, "I can write SQL with my eyes closed."
But something doesn't look quite right. Upon closer examination, you see that database queries aren't written in SQL, but some query language you've never seen before.
You go to your manager's office and ask her about it.
"Oh yeah," she says, "We didn't have time to learn how to setup an existing database, and our needs were pretty simple at the time. We decided to roll our own, lightweight database with a simplified query language. I guess it sort of grew over time as our needs grew."
Horrified, you tell her that you don't think it's going to be a good fit, turn in your badge, and head to your car.
Unfortunately, when you land your next job, the above scenario plays out all over again. Instead of using SQL, you discover that they too have rolled their own custom, ad hoc querying language! This repeats, over and over, until your descent into madness is complete and you retire to a cabin in the woods.
While this hopefully sounds like something out of a nightmare, the sad fact is that this is precisely the state of the art when it comes to writing web JSON APIs. Whether you're writing an Ember.js application, a mobile app for Android or iOS, or a desktop app, anything that consumes a web API typically has to deal with URL patterns and JSON structures that are ad hoc and informally-specified.
This is bad. Even though we have figured out a standard way of describing models and their relationships on the server, getting them into the browser requires every developer write custom, imperative code. It's a colossal waste of human time and energy.
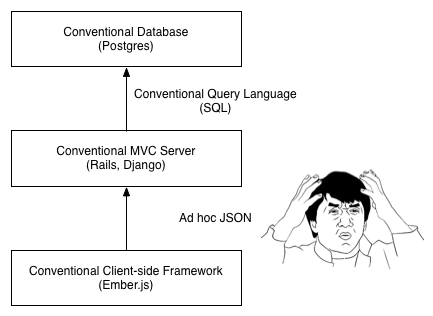
The good news is that the solution is now more apparent: if you have a conventional framework on the server and a conventional framework on the client, they should be able to communicate, automatically, using a standard interchange format.
The reality, however, is that Ember.js developers need to use existing APIs that aren't 100% consistent. While we were building towards the future, we were also trying to build something that could be used in the interim. In retrospect, trying to meet both goals muddled our message, confused users, and complicated the architecture.
Instead, Ember Data will now focus on being the best possible library for Ember.js apps to communicate with consistent, conventional APIs.
We will leave bridging the gap in the very capable hands of simpler libraries that require less conceptual overhead to work with custom JSON APIs, such as:
To be clear: Ember Data will not be limited to one particular convention. We are excited to see the number of third-party adapters, such as those for Parse, Django, localStorage, and Firebase, continue to grow. The only important feature is that the interchange between Ember Data and the backend be consistent across all models and their relationships.
What Does This Mean?
Most users of Ember Data will not have to make any changes to their
application. If you are using the REST adapter with something like the
ActiveModel::Serializers gem in Ruby on Rails, you will continue to not
have to write any network code—defining your schema in JavaScript is
enough for us to know how to load data from the server.
The only notable immediate change is that we will be removing the
BasicAdapter that we described in last month's blog post. This adapter
was designed to be a stopgap measure to help people use Ember Data with
ad hoc JSON APIs, but we committed the cardinal sin of inventing an API
instead of extracting it from a real application as we usually do.
Developers who had tried out the BasicAdapter appreciated our efforts, but
found it lacking in several important areas. We believe focus is
important, so we will be focusing our efforts on conventional APIs and
will leave the cases previously covered by the BasicAdapter to other
libraries.
The other change is that we will be updating the documentation on the Ember.js website to reflect this new focus, as well as providing documentation on how to connect Ember apps to less well-defined JSON APIs.
JSON API
In order for Ember Data apps to communicate with a server automatically, the interchange format must be semantically rich enough to capture all of the changes to models and their relationships that you may make on the client.
Over time, we have been building more functionality into the JSON
format used by the RESTAdapter. We have decided to formalize this
JSON format so that any backend, whether it be Ruby on Rails, Django,
node.js, or your other favorite server technology, can interact with
Ember.js apps without users having to write network code.
We have begun the process of documenting this format at JSONAPI.org with Brian Shirai. This is a living document that formally describes the JSON format we hope that the authors of server-side frameworks will use to get seamless compatibility with Ember.js applications. Other JavaScript framework are encouraged to adopt this format so that they can get the same benefit.
Because the best standards are driven by real implementations, Steve
Klabnik and Santiago
Pastorino (both major contributors to
Ruby on Rails) have volunteered to integrate this specification into the
rails-api and ActiveModel::Serializers projects. This
proof-of-concept will allow us to verify the specification is solving
real-world problems.
This work will make it easier for Ember.js developers to integrate with Ruby on Rails, and we hope other server-side frameworks vendors follow suit.
The RESTAdapter will continue to be configurable, so if you
want to use a JSON API that differs from the default specification, but
is still consistent across all of your models, you don't have to write
an adapter from scratch.
Regular Releases
Now that Ember Data is stabilizing rapidly, we will start doing regular beta releases to make it easier for users to communicate about different versions. The first release, which we'll be releasing in the next few days, will be version 0.13. In keeping with the SemVer standard, we reserve the right to change public APIs until we reach a 1.0.0 candidate. That being said, we will try our best to continue keeping the app-facing API stable.
We're excited about the future of Ember Data. In the same way we fought for strong application architecture conventions in the browser, we will continue to fight for better compatibility between the client and server. Hopefully soon, writing low-level XHR code will be an optional optimization, not a requirement.